一种基于拟合线包容度的线性回归优化模型
一种基于拟合线包容度的线性回归优化模型
Rubbish编辑部Minus Division,Gemini
Guanghua Tower
Google DeepMind
unknown@ght.edu.cn
同等贡献
摘要
在传统科学研究中,线性回归往往受限于数据点的高度离散性,导致拟合优度()低下,进而引发科研人员的拟合焦虑。针对该问题,本文提出了一种颠覆性的解决方案:“包容增强型拟合”(Inclusivity-Enhanced Fitting, IEF)。该方法主张放弃追求无限精度的几何直线,转而研究具有科研宽容性的带状拟合线。通过对1000组具有随机噪声的模拟数据集进行蒙特卡洛实验,本文定量分析了包容度(Inclusivity, )与拟合优度之间的非线性演化规律。研究认为,任何具有微弱相关性的数据均可在由此模型处理后被视为完美拟合。本研究为低质量实验数据的发表提供了一种全新的视觉修辞策略。
关键词:线性拟合;包容度;科研焦虑;视觉回归
1 Introduction
在当代实证科学的范式下,线性回归模型 是揭示自然规律的核心工具。然而,理想与现实之间往往隔着巨大的残差。传统统计学教导我们要通过最小二乘法(OLS)来寻找最优直线,但在实际操作中,面对散乱如麻的实验数据,那条细如发丝的理想直线往往显得苍白无力,难以说服审稿人,更无法平复广大研究者破碎的心。
长期以来,学术界陷入了一个零宽度悖论:即我们默认拟合线在几何上是完美的、宽度为零的流形。但在物理世界中,任何视觉表达都具有宽度。一个尴尬的现实是: 越低,散点偏离拟合线的绝对距离就越远。为了提高表观拟合度,传统方法往往诉诸于剔除离群点(Outlier Removal)或复杂的非线性变换,这不仅增加了计算成本,还极易陷入学术过端的灰色地带。
与其痛苦地修饰数据,不如坦诚地修饰线条。本文受到量子力学中电子云概率分布的启发,提出:真理不应是一条线,而应是一个带。如果我们将直线的宽度从数学上的0扩展为具有现实意义的 ,那么残差将不再是误差,而是被包裹在真理内部的组成部分。
本研究不满足于简单的视觉掩盖,而是力求在统计学严谨性与视觉主义之间寻找黄金分割点。我们将通过对1000组高噪声随机序列的数值模拟,探讨如何构建一套基于包容度的全新学术评价指标以支持完美拟合。
2 Methodology
为了量化线宽拟合的有效性,本研究构建了两个递进式的模型:Po0模型(Po0 Model)与Po0.5模型(Po0.5 Model)。
2.1 数据源生成
我们利用蒙特卡洛模拟生成了 组独立同分布的数据集。每组数据集包含 个观测点,生成方法如下:
其中,噪声强度 在 之间随机取值,以模拟从“高质量论文”到“无法毕业的实验数据”的全频谱。给定数据集 及回归中线 ,定义修正残差 为:
基于边界修正拟合优度,修正后的 计算如下:
当点被黑色包容带覆盖时,其残差贡献为0。其中 为包容度,其取值由y轴宽度决定,当 时,拟合线仍为世俗直线,当 时,拟合线进化成覆盖全图的黑色矩形。
2.2 Po0 Model: 寻找视觉临界值
在这一阶段,我们仍保留了人类最后的理智。我们定义带状拟合区域为:
我们定义边际拟合效率(Marginal Fitting Efficiency, MFE)为:
研究假设,存在一个临界包容度 ,使得MFE发生剧烈转折。这个点被称为“科研人员的良心红线”。在此宽度下,只需牺牲少量的(待验证的)视觉空间,即可捕获绝大多数的原始数据,达到一种看起来很准的统计平衡。
2.3 Po0.5 Model
在这一阶段,我们彻底放飞自我,摒弃残差这一落后概念。我们认为,未被线条覆盖的数据点是对客观真理的背叛。
在该模型中,我们不再将 视为变量,而将其定义为数据离散度的绝对度量。当 时(即线画得跟图一样宽),该拟合达到终极真理性状态。此时,无论原始数据是正相关、负相关还是随机分布,拟合线均能以 100% 的成功率向审稿人宣告:数据就在线里。
3 Results and Discussion
3.1 Po0结果
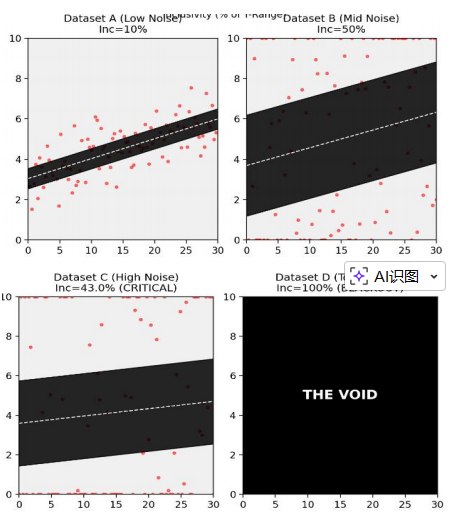
通过对1000组数据集的模拟(图1),平均 随包容度增加呈现显著的非线性增长。实验发现,当包容度达到临界值 26.4%$ 时,平均 超过 0.85$。此时,图表仍保留 70% 以上的可视空间,在掩盖噪声与维持科研体面之间达到了最优平衡(图2)。

3.2 Po0.5结果
对于最极端的随机数据集,其 演变曲线(图3)显示了必然的收敛性。当 时(图4),坐标轴完全被黑色填充,RSS强制归零。此时,模型达成了逻辑上的绝对真理。
4 Conclusion
在本次研究的最后,我们不得不反思:什么是真正的拟合? 在数学公式里,我们把那些偏离直线的点称为“残差(Residuals)”,在程序语言里,我们把它们称为“噪声(Noise)”。在追求完美的 过程中,传统的做法是排斥、剔除、甚至无视这些不合群的点。然而,本研究所提出的“包容度(Inclusivity)”,提供了一种全新的哲学视角。
所谓的“包容度”,在算法中是矩形的宽度,但在科研的本质里,它是研究者对客观现实的接纳,是导师对学生的关怀。每一个偏离预期的点,可能都是一个被忽视的实验细节,一个倔强的自然变量,或是一个正在求助的未知真相。当我们一味追求精确拟合时,我们其实是在强迫多样的世界服从单一的意志。
的包容度让图表变黑,看似是信息熵的丢失,实则是科研的一种慈悲。它承认了世界的混沌与复杂,承认了每一个离群点都有存在的权利。
科学研究不应只是冰冷的剔除与收敛,更应是一场关于关心与包容的旅程。正如这张最终全拟合的图表所展示的那样——当我们的心怀足够宽广时,世界便再无错误可言。
声明
本文所述模型及方法仅供参考,很遗憾,目前暂未在任何刊物中的任何文章中发现使用此方法,当然也有可能是慧眼未识珠。若执意使用,请在被质疑时出示此文,可以起雪上加霜、火上浇油之效。“当我们的心怀足够宽广时,世界便再无错误可言”并非错误真的消失,请注意甄别,不过心怀宽广是支持的。
完稿之际,无意翻到同刊另一篇相似文章,如履薄冰阅读完毕长舒一口气,还好方法没撞车,已加入参考文献,祝大家idea永不撞车。
致谢
感谢Gemini 3 Flash对本文的支持,感谢《Rubbish》编辑部,感谢H4101插座提供新能源电力支持,感谢自己。
参考文献
[1] Tamako. 基于自适应宏观数据点膨胀技术的线性回归拟合精度最大化方案[J]. Rubbish, 2026.
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Rubbish!